Catégorie :
GuideCet article est la partie pratique pour la création d’une box boot2root. Vous pouvez retrouver la première partie théorique ici
Introduction :
Dans cet article qui suit la logique du premier on va mettre en pratique ce qui a été vu précédemment. Cela va se faire grâce à la création d’une box plutôt simple orientée pour les débutants.
Tout ce que je vais indiquer ici seront des exemples choisis parce qu’ils sont rapide à mettre en place et facile à expliquer. Cependant rien ne vous empêche de votre côté de reprendre ce qu’on va faire ici et de modifier à votre sauce.
On va garder la même structure que pour le premier article. Cependant il se peut que l’ordre des étapes ne soit pas identique. Pourquoi ? Parce que comme précisé précédemment, tout n’est pas fixé à l’avance. C’est une sorte de marche à suivre pour avoir une vision globale du projet. C’est aussi en fonction des préférences de chacun.
Ce que nous allons aborder :
- Préparation et réflexion à la création de la box :
- Mise en place et configuration technique :
- Conclusion
Préparation et réflexion à la création de la box
Pour prendre exemple sur l’article concernant la théorie, c’est ici qu’on va réfléchir à toutes les idées histoire d’avoir en tête un schéma à suivre pour ensuite gagner du temps lors de la mise en place technique.
Public visé
Cette fois-ci on ne va pas commencer par la prise de notes mais bien par le public visé. Déjà pour vous montrer qu’on peut très bien faire dans un ordre différent selon les besoins, mais aussi parce qu’ici ça nous arrange de d’abord commencer par cette étape.
En effet, l’article a pour but d’être une aide pour les débutants. On a donc déjà notre public visé.
Prise de notes
En connaissant à l’avance le public visé, j’ai défini une liste de plusieurs idées qui me sont passées par la tête et qui peuvent être orientées vers les débutants (encore une fois rien n’est fixé).
On va directement rentrer dans le concret en vous montrant le texte brut que j’ai écrit pour cet article concernant les idées pour la box qu’on va créer ici :
- Site Wordpress avec vulnérabilité
- Privesc avec commande
man - Obtenir premier shell avec smb -> écriture disponible donc upload shell et navigation dans le répertoire web correspondant pour l’exécuter
- Fuzzing web pour obtenir le répertoire smb
- Brute force passphrase clé SSH
- Mot de passe dans le code source encodé dans une base (base64, base32 …)
- Etude d’une capture wireshark avec les identifiants à l’intérieur
- Privesc avec commande
vimvia sudo - Privesc avec SUID
- Découverte d’un mot de passe avec de l’OSINT (compte Twitter par exemple)
- LFI sur le site web
- Serveur FTP
On voit déjà que toutes les idées ne seront pas utilisées parce que certaines rentrent en contradiction avec d’autres. Mais ce n’est pas grave puisqu’on pourra les garder de côté pour une potentielle future box.
Cette liste regroupe non seulement des vecteurs d’attaque comme les escalations de privilèges, le brute force, LFI, etc … Mais aussi des idées de scénario.
Si dans la suite des étapes on se rend compte qu’une idée ne fonctionne pas ou bien qu’on en a une nouvelle en tête, on va pouvoir modifier cette liste à notre guise.
On fera le tri par la suite lorsqu’on parlera du scénario.
Flags
On reste sur du basique avec seulement 2 flags. Le user et le root.
On va donc générer deux hash aléatoires. On va pouvoir faire ça directement sur Linux (ou bien sur les sites de hash) :
echo -n "this is my user flag" | md5sum #User flag
echo -n "this is another root flag" | md5sum #Root flag
On va donc obtenir :
User flag -> 01846f86f9285ca468eb3618db462ab1
Root flag -> b1970313271d6e36bb343cd8e671b087
On les garde de côté pour ensuite les ajouter aux fichiers qu’on nommera par exemple user.txt et root.txt.
Scénario
A partir de cette étape on va pouvoir construire concrètement le chemin à suivre pour que l’utilisateur puisse attaquer notre machine vulnérable.
On va donc se baser sur la liste qu’on avant plus haut et pour chaque idée on va voir ce qu’on peut en faire :
- Site Wordpress pas assez adapaté pour le personnaliser et ajouter des vulnérabilités manuelles. Donc choix d’un set up de site manuellement.
- Pour bien aller avec ce site -> serveur SMB mal configuré ce qui va nous permettre d’upload un reverse shell dedans et de le déclancher via le site web.
- Fuzzing sur le site web pour trouver le répertoire caché qui est lié à smb pour l’exécution.
- Serveur FTP est en trop mais on peut quand même le rendre accessible en anonymous avec rien d’important à l’intérieur pour brouiller les pistes / rabbit hole.
- Le brute force de la clé SSH sera compliqué à mettre en place dans note cas donc je laisse de côté pour une autre fois.
- Le mot de passe dans le code source n’est pas non plus adapté car pas besoin de mot de passe dans notre cas. On aurait pu utiliser ce mot de passe pour donner accès au ftp par exemple.
- Plusieurs possibilités de privesc. Ici on considère que l’utilisateur aura un shell via un reverse shell donc il arrivera sur la machine en tant que
www-data. Donc il faut penser à passer en tant qu’utilisateur puis en tant que root. Donc au moins 2 privesc. On peut choisir celle avec un binaire en SUID. On va devenir root grâce à la commande “man”. Le sudo avec Vim aurait aussi pu être intégré mais il est vraiment plus courant. On aurait pu également laisser trainer une capture wireshark dans la machine mais on a déjà ce qu’il nous faut. - La découverte d’un mot de passe avec de l’OSINT aurait été une très bonne idée pour une box orientée réaliste par exemple. Cependant dans notre box on a déjà notre première phase d’approche donc encore une fois on laisse de côté.
- Pareil pour la LFI, pas besoin puisqu’on a déjà notre façon de rentrer sur la machine.
Maintenant qu’on a fait le tri dans toutes les idées voici un petit récapitulatif de ce qu’on va mettre en place :
- Serveur FTP pour brouiller les pistes.
- Serveur SMB pour y upload un reverse shell.
- Serveur Web pour exéucter le reverse shell qu’on aura upload via SMB et obtenir un shell sur la machine.
- Privesc de www-data au premier user grâce à un binaire SUID
- Privesc du user au root avec la commande “man”
Mise en place et configuration technique
On sait ce qu’on veut mettre en place, il ne nous reste plus qu’à se concentrer sur la partie technique pour implémenter toutes nos idées.
Choisir son OS
En fonction des vulnérabilités trouvées dans la partie “prise de notes” on sait déjà qu’on va utiliser du Linux.
Pour la distribution Ubuntu ou Debian ferait très bien l’affaire. Je pars donc sur une Debian (encore une question de préférence).
Choix du système de virtualisation
Cette partie est également très rapide. J’ai l’habitude d’utiliser VirtualBox, il permet de faire des sauvegardes plutôt facilement.
Vous pourrez le télécharger directement sur le site officiel.
Installation Debian
La première chose à faire est de télécharger une image ISO de Debian directement sur le site officiel.
Il faut choisir en fonction de votre architecture processeur mais le plus souvent ce sera amd64 pour du 64 bits ou i386 pour du 32 bits.

Une fois en possession de cette image on va donc créer une nouvelle machine vierge sur VirtualBox.
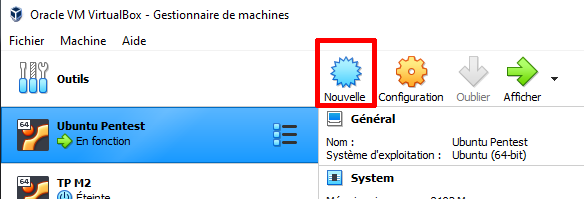
Comme nous allons installer une machine Debian il faut choisir les bonnes options. Vous pouvez appeler votre box comme bon vous semble ça n’aura pas d’incidents par la suite. Le nom sera affiché dans la liste des machines à gauche une fois créée.
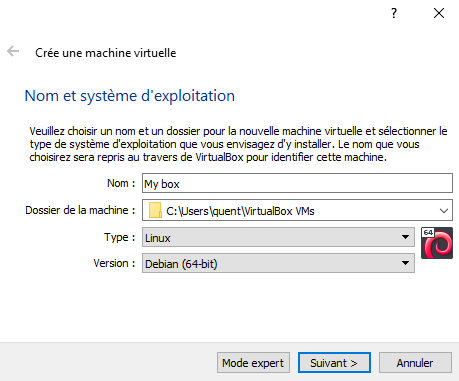
Attention lorsqu’on vous demande de choisir la taille du disque à sélectionner une taille suffisante pour ce dont vous avez à faire. En général 3-4 GB suffisent (très) largement.
Il faut aussi spécifier avec quelle image la machine virtuelle doit démarrer. On a télécharger notre image Debian et donc il faut la spécifier.
On se rend dans le menu “Stockage”, on sélectionne le disque vide de la partie Contrôleur : IDE et à droite on va venir cliquer sur le petit CD et aller chercher notre image disque qu’on vient de télécharger (si vous ne l’avez pas déplacé alors il se situe dans le dossier de téléchargement).
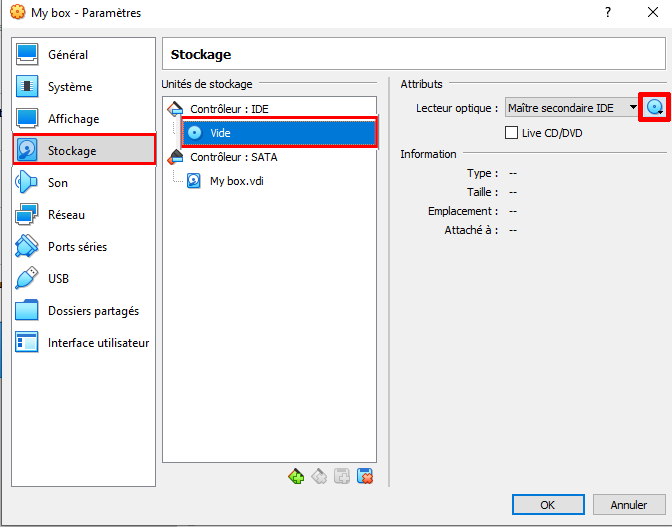
Suite à la sélection de l’image on doit obtenir quelque chose de semblable à ceci :
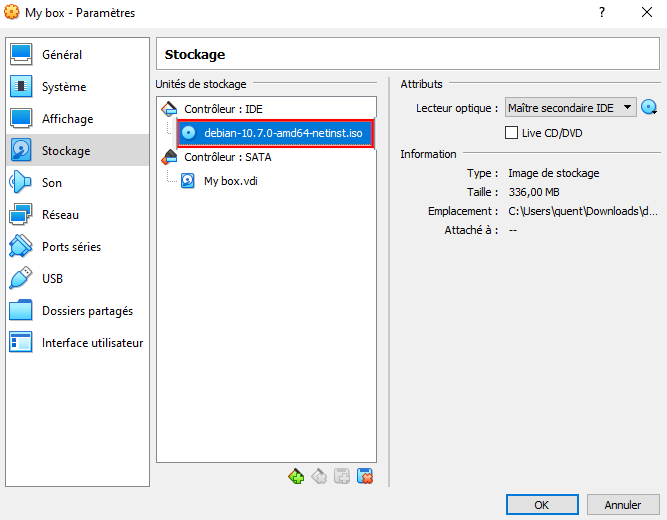
Par défaut la carte réseau est en NAT. On va la modifier pour la mettre en mode pont. De ce fait notre machine virtuelle aura une adresse IP assignée par notre DHCP comme si c’était une “vraie” machine physique du réseau.
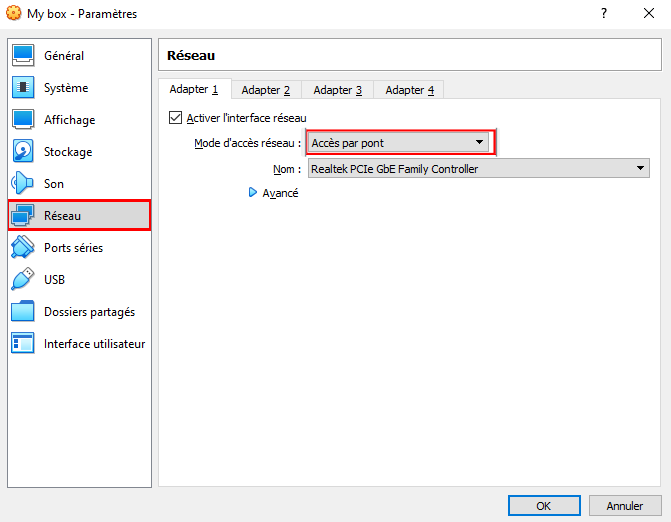
On est prêt à lancer la machine virtuelle en la sélectionnant dans la liste de gauche et en cliquant sur la flèche verte “Démarrer”.
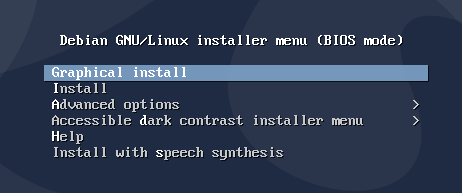
On se retrouve désormais à devoir installer Debian. Je vais montrer ici que les étapes qui ne sont pas forcéments intuitives. Pour le reste ça ne devrait pas trop poser de problèmes. La plupart du temps il suffit de faire suivant sans changer les paramètres de base.
Pour ceux qui ne sont pas habitués avec la ligne de commande ça va être compliqué puisqu’on va faire presque que ça pour configurer les différents services de notre box. Cependant, si vous voulez profiter de votre dernier instant avec une souris vous pouvez faire une installation graphique ;)
On va donc vous demander plein d’informations différentes comme par exemple votre pays, la configuration de votre clavier, etc … Je considère que vous êtes assez grands pour faire ce genre de choses.
Pour ce qui est de la partie choix du nom d’hôte, de l’utilisateur, du root et de leur mot de passe vous pouvez mettre ce que vous voulez puisque vous pourrez modifier par la suite.
Je vous conseille quand même de mettre des mots de passe faciles à mémoriser lors de la configuration des différents services, ça vous fera gagner du temps. Le nom d’hôte sera affiché dans votre shell derrière le nom de l’utilisateur courant. Vous pourrez aussi le modifier par la suite.
N’oubliez pas de noter tous vos mots de passe pour vous en souvenir plus tard !
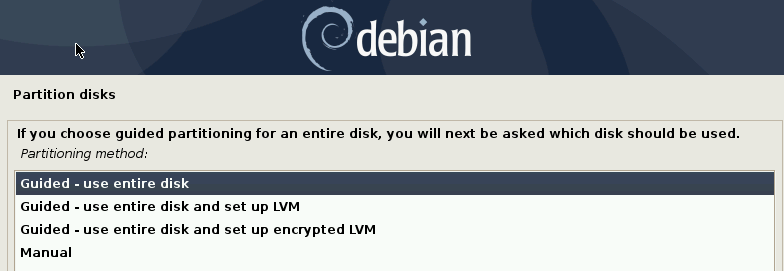
La partie la plus “compliquée” est le partitionnage. Heureusement dans notre cas on va faire quelque chose de basique puisqu’on va utiliser tout le disque pour y installer Debian.
Encore une fois ici on fait quelque chose de facile et simple volontairement mais évidemment, si vous savez que votre machine finale sera très lourde alors vous pouvez optimiser l’espace alloué en partitionnant manuellement le disque.
Dans notre cas on va supprimer tout le disque pour y installer Debian.
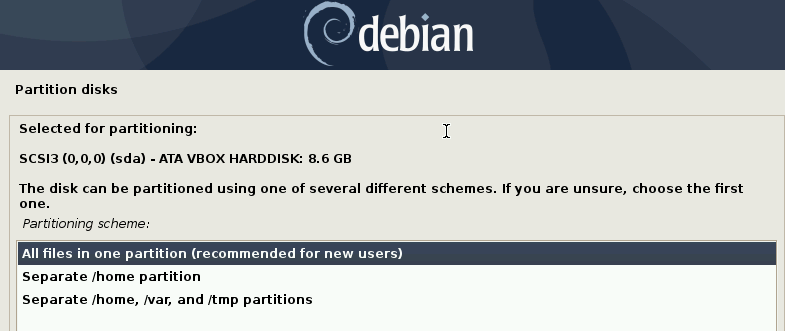
L’installation va ensuite prendre de longues minutes.
On vous demandera par la suite si vous voulez scanner un autre disque, dans ce cas répondez “Non”.
Lorsqu’on vous demandera un proxy laissez le champ vide.
Encore une fois il faut attendre que l’installation se fasse.
On arrive à la partie où on va installer les services de base pour notre Debian.
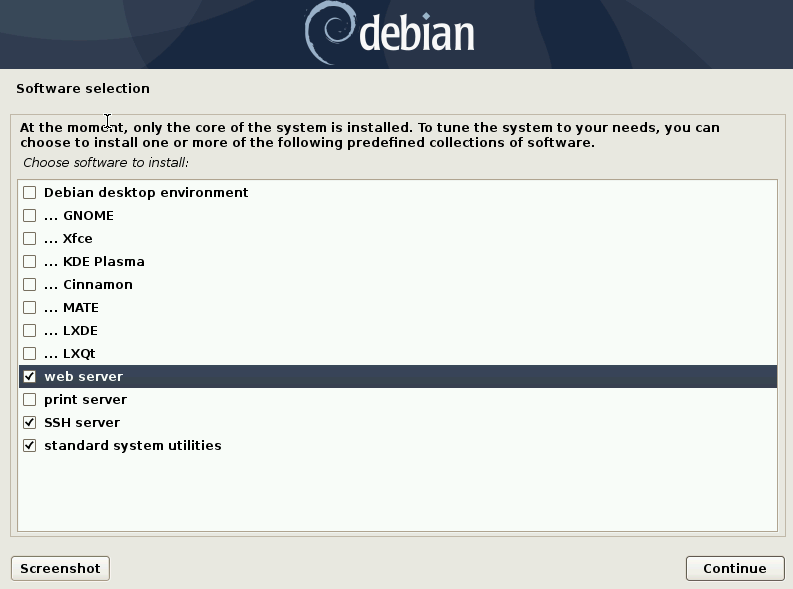
On ne va pas cocher la case pour avoir un Desktop Environment. Parce que déjà ça va alourdir la machine pour rien et ensuite parce qu’il faut vous forcer à vous habituer à la ligne de commande (si ce n’est pas déjà le cas). Vous verrez c’est sympa. Promis.
Le reste dépend un peu du scénario de votre machine. S’il contient un site web alors cochez la case “web server”.
Je vous conseille quand même d’installer un server SSH. Ce sera beaucoup plus simple par la suite pour configurer la box. Vous pourrez toujours désinstaller SSH à la fin.
On garde également les “standard system utilities”.
On va ensuite installer grub pour que notre machine puisse boot.

On l’installe au même emplacement que notre disque principal (de toute façon on n’a pas trop le choix).
On arrive à la fin de l’installation !
Normalement le système devrait redémarrer et si tout s’est bien passé alors au redémarrage on doit tomber sur le menu grub
On atterit alors sur la page de login de la machine.
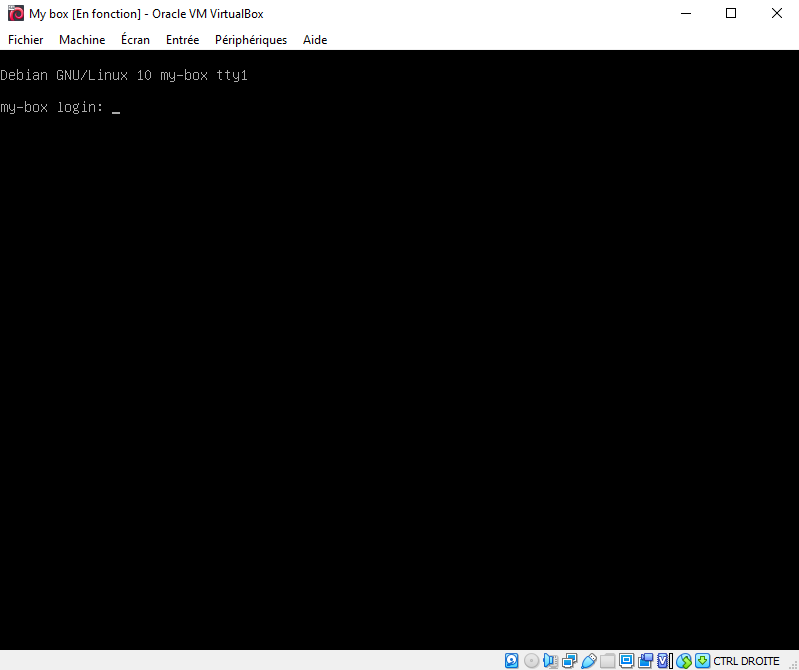
Si vous êtes arrivés jusqu’ici alors bravo à vous. Maintenant dépèchez vous de faire une sauvegarde de votre VM pour éviter de recommencer toutes ces étapes !
Sauvegardes
Les sauvegardes sont font de manière très simple via VirtualBox.
Il faut tout d’abord éteindre la machine que l’on veut sauvegarder.
Il suffit de sélectionner dans la liste de gauche la machine qui vous voulez sauvegarder, de faire un clic droit dessus et de sélectionner “Cloner”. On va alors vous demander de faire un choix entre deux types de clonages différents. Sélectionnez “clone intégral” et donnez lui un nom explicite. Par exemple “Ma_box_Debian_base” ou quelque chose qui vous indique que c’est votre machine Debian de base après avoir fait l’installation de base.
Vous devriez vous retrouver désormais avec 2 machines dans votre liste de gauche. La nouvelle créée et l’ancienne. Vous pouvez reprendre l’ancienne pour continuer vos configurations dessus.
Si jamais vous avez un problème et que vous devez reprendre celle de base alors vous pourrez supprimer l’ancienne et reprendre depuis celle qui est toute fraîche.
Ici aussi faîtes attention à bien refaire une sauvegarde de cette machine pour ne pas avoir à tout recommencer en cas d’erreur. Puisque cette machine sera modifiée.
Voici un petit exemple de la liste des machines qu’on aura à la fin de notre configuration :
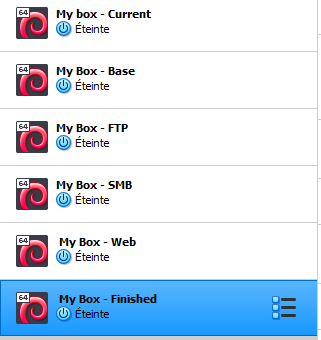
J’ai fait en sorte que la sauvegarde suivante contienne les services fonctionnels des précédentes.
C’est à dire que la sauvegarde qui s’appelle “My box - Web” contient le service Web fonctionnel mais aussi le SMB et le FTP.
Accès à la machine
Lors de l’installation nous avons installé un serveur SSH pour faciliter la configuration de notre machine vulnérable.
On va donc l’utiliser pour la suite de ce guide. Ça nous permet d’accéder à la box via notre machine principale et donc on va pouvoir utiliser certaines fonctionnalités qui ne sont pas disponibles si on y accède directement sur la machine. On peut citer le copier/coller ou bien la taille de l’écran qui nous permet d’être plus à l’aise.
Pour connaître l’adresse IP attribuée à la box il y a plusieurs possibilités.
On peut se rendre directement sur la machine pour récupérer cette adresse. Sur la page de login on rentre les infos renseignées lors de l’installation et de la création des utilisateurs. Il suffit ensuite de lancer la commande :
ip -c a
Pour afficher toutes les interfaces de la machine. On va alors récupérer l’adresse qui doit être en 192.168.X.X
L’autre possibilité est d’utiliser nmap ou netdiscover. Avec cette méthode on ne va pas avoir besoin de se connecter à la machine au préalable pour récupérer l’adresse IP.
Avec nmap il suffit de faire un ping scan :
nmap -sP 192.168.1.0/24
De votre côté peut-être qu’il faudra modifier l’adresse réseau. Ça dépend de votre plage d’adresse. Le plus souvent vous trouverez 192.168.1.0/24 ou 192.168.0.0/24.
Vous devriez avoir comme résultat une liste d’adresses IP plus ou moins grande en fonction des appareils connectés sur votre réseau. Il faut alors définir celle qui correspond à notre box. Normalement elle devrait être identifiée par le hostname qui vous avez indiqué lors de la création de la machine dans l’installateur Debian.
Pour ma part il s’agit de l’adresse 192.168.1.44.
On va donc se connecter avec SSH à la machine :
ssh user@192.168.1.44
Evidemment remplacez user par votre nom d’utilisateur et l’IP par la votre. On vous demandera ensuite le mot de passe.
Par défaut sudo n’est pas installé ici. Vous pouvez le faire de votre côté ou bien vous pouvez vous connecter au compte root avec :
su root #Puis entrez votre mot de passe quand demandé
FTP
On commence la configuration de notre machine par la serveur FTP. L’ordre d’installation n’a pas d’importance. Il faut tout d’abord commencer par mettre à jour le système :
apt update
Pour l’installation et la configuration je me suis basé sur ce guide : https://wiki.debian.org/fr/vsftpd.
On installe le serveur FTP :
apt install vsftpd
On stop le service avant de modifier les fichiers :
service vsftpd stop
On peut désormais modifier la configuration du serveur FTP. Pour cela on va modifier le fichier /etc/vsftpd.conf.
On va modifier la ligne suivante avec la valeur correspondante :
anonymous_enable=YES
Cela va nous permettre d’autoriser l’accès en anonyme au serveur FTP (donc sans avoir besoin de mot de passe).
On va créer un nouveau répertoire qui va contenir un fichier qui correspond à une voie sans issue :
mkdir /srv/ftp
echo "Try harder :p" > /srv/ftp/.secret
On va y créer un fichier nommé .secret à l’intérieur qui contient la phrase “Try harder :p”. C’est donc une fausse piste et l’utilisateur va devoir trouver une autre façon de rentrer sur le système.
Il faut redémarrer le service :
service vsftpd start
Tests
Pour valider notre configuration on va tenter de se connecter en anonyme sur notre serveur FTP :
ftp 192.168.1.44
On va préciser comme utilisateur anonymous et on va rentrer un mot de passe vide.
Si la connexion a bien été établie on devrait obtenir ceci :
Connected to 192.168.1.44.
220 (vsFTPd 3.0.3)
Name (192.168.1.44:krowz): anonymous
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp>
On peut ensuite vérifier qu’on possède bien le fichier .secret à l’intérieur et qu’on peut le récupérer :
ftp> ls -la
200 PORT command successful. Consider using PASV.
150 Here comes the directory listing.
drwxr-xr-x 2 0 113 4096 Jan 13 09:39 .
drwxr-xr-x 2 0 113 4096 Jan 13 09:39 ..
-rw-r--r-- 1 0 0 14 Jan 13 09:39 .secret
226 Directory send OK.
ftp> get .secret
local: .secret remote: .secret
200 PORT command successful. Consider using PASV.
150 Opening BINARY mode data connection for .secret (14 bytes).
226 Transfer complete.
14 bytes received in 0.00 secs (184.7551 kB/s)
ftp> exit
Si on tente d’afficher ce fichier téléchargé alors on retrouve notre fameuse phrase “Try harder :p”.
Si vous avez réussi à faire ce que vous vouliez alors je vous conseille de faire une sauvegarde.
On peut alors passer à la partie suivante.
SMB
J’ai réalisé cette partie grâce à cette documentation : https://wiki.debian.org/Samba/ServerSimple
Comme pour FTP on va installer le serveur Samba :
apt install samba
Le fichier de configuration de se serveur se situe ici : /etc/samba/smb.conf.
On va aller le modifier pour y ajouter à la fin les lignes suivantes :
[Default]
comment = This is the default SMB share
read only = no
path = /var/www/html/writable
guest ok = yes
Cela va nous permettre de créer un nouveau share qui sera accessible par l’utilisateur. Il pourra écrire dedans et donc upload un reverse shell qu’il exploitera depuis le web.
- [Default] est le nom du share.
- comment est un commentaire qui décrit le share
- read_only = no permet d’autoriser l’utilisateur à écrire sur le share
- path = /var/www/html/writable va définir un chemin vers l’endroit où se situe notre répertoire partagé via SMB.
- guest ok = yes permet de se connecter au share sans avoir besoin de connaître le mot de passe. De la même manière que le compte anonymous pour FTP.
J’ai choisi le nom de répertoire writable pour qu’il soit dans une liste qu’on pourra utiliser pour du fuzzing web.
Ça ne sert à rien de vouloir mettre un répertoire ultra compliqué qui ne sera pas trouvable ou très compliqué à trouver.
On met à jour les modifications qu’on vient d’effectuer :
/etc/init.d/smbd restart
Tests
Sous Linux, pour lister la liste des dossiers partagés d’un serveur il suffit d’utiliser l’utilitaire smbclient :
smbclient -L 192.168.1.44
Dans notre cas on obtient le résultat suivant :
smbclient -L 192.168.1.44
Enter WORKGROUP\root's password:
Sharename Type Comment
--------- ---- -------
print$ Disk Printer Drivers
Default Disk This is the default SMB share
IPC$ IPC IPC Service (Samba 4.9.5-Debian)
SMB1 disabled -- no workgroup available
On peut voir que la commande nous demande un mot de passe root. Il suffit de ne rien renseigner et juste d’appuyer sur la touche Entrée.
On se retrouve alors avec une liste des différents dossiers partagés. Celui qui nous intéresse est celui qui est nommé Default.
Si on tente de s’y connecter :
smbclient //192.168.1.44/Default
Le mot de passe root va de nouveau être demandé mais comme auparavant on ne va rien mettre dans le champ.
Enter WORKGROUP\krowz's password:
Try "help" to get a list of possible commands.
smb: \> ls
. D 0 Wed Jan 13 17:28:17 2021
.. D 0 Fri Jan 8 14:26:31 2021
7205476 blocks of size 1024. 5406012 blocks available
smb: \>
On doit pouvoir accéder au dossier partagé et on obtient le résultat ci-dessus.
Sur ma machine je suis dans un répertoire où il y a un fichier nommé test.txt.
Je vais tenter de l’upload sur la machine cible sia SMB :
Enter WORKGROUP\root's password:
Try "help" to get a list of possible commands.
smb: \> put test.txt
putting file test.txt as \test.txt (0,0 kb/s) (average 0,0 kb/s)
smb: \> ls
. D 0 Wed Jan 13 17:31:50 2021
.. D 0 Fri Jan 8 14:26:31 2021
test.txt A 0 Wed Jan 13 17:31:50 2021
7205476 blocks of size 1024. 5406012 blocks available
smb: \>
L’upload s’est bien effectué et on retrouve le fichier dans le dossier partagé.
Encore une fois je vous conseille de sauvegarder votre box pour éviter de mauvaises surprises.
Web
Le serveur web est déjà présent puisqu’on l’a installé en même temps que SSH lors de la configuration de Debian tout au début.
Le chemin par défaut est le suivant : /var/www/html
Tout ce qui se situe à la racine de ce dossier sera à la racine de votre site web.
Par exemple si vous ajoutez un fichier bonjour.txt dans /var/www/html, ce qui donne /var/www/html/bonjour.txt alors on pourra y accéder grâce au site via http://ip_du_site/bonjour.txt
On peut ensuite ajouter d’autres fichiers ou dossiers. Pour les dossiers on va à chaque fois y accéder en ajouter un nouveau / dans l’URL.
De notre côté il faut en créer un nouveau qui correspond au dossier partagé samba.
mkdir /var/www/html/writable
Attention ! Ne pas oublier de mettre le droit write sur le dossier où sera les fichiers dans SMB :
chmod o+w /var/www/html/writable
Si cette opération n’est pas effectuée alors on ne pourra pas upload de nouveau fichier dans ce dossier. On va donc donner le droit d’écriture à tous les autres groupes du répertoire. On rappelle que le répertoire appartient à l’utilisateur système www-data:www-data.
Il nous faut cependant encore installer PHP. Parce qu’on va vouloir que l’utilisateur puisse obtenir un shell sur la machine grâce à un reverse shell qui sera exécuté par php :
apt install php
Si on se rend sur le site actuel de notre machine ça va vous paraître bien triste puisque c’est la page par défaut. Si vous voulez lui donner un air de “vrai site” alors vous pouvez trouver sur Internet des templates gratuits.
Dans notre cas j’ai décidé d’en utiliser un de ce site : https://www.free-css.com/free-css-templates.
Une fois téléchargé il faut le transférer sur la box :
#Depuis notre machine principale :
scp -r website_template krowz@192.168.1.44:/home/krowz
De retour sur notre box on va déplacer le fichier dans /var/www/html. Je l’ai fait en plusieurs étapes à cause de certains droits qui m’empêchaient de directement l’upload dans le bon répertoire.
cd /home/krowz/website_template
mv * /var/www/html
Cependant ça reste un site par défaut et donc si vous voulez lui donne plus de crédibilité alors vous devrez le modifier par vous même.
Par exemple modifier certains liens, le titre, les catégories …
Tests
On peut se rendre sur le site web via le navigateur en http://IP , IP étant évidemment l’adresse IP de la machine.
On doit alors tomber sur notre magnifique site web avec notre beau CSS.
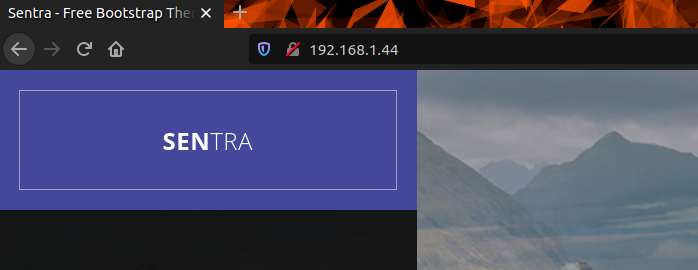
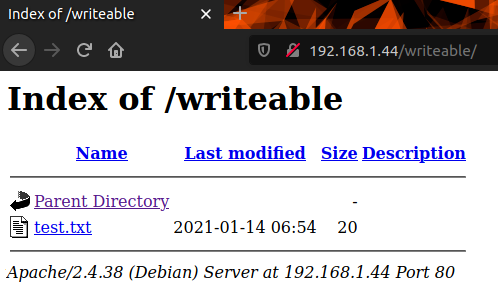
Si on se rend à l’URL suivante on est censé avoir accès au répertoire et même à test.txt qu’on a upload juste avant via smb : http://192.168.1.44/writable/
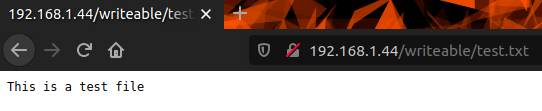
Privesc utilisateur
L’utilisateur va obtenir un shell sur la machine grâce à un reverse shell qu’il aura upload via SMB et accédé via le web. Le service web est lancé par un utilisateur système qui s’appelle www-data.
De ce fait quand l’attaquant arrive sur la machine il est connecté en tant que www-data.
Il va donc falloir qu’il gagne les droits de l’utilisateur avec les droits plus élevés sur la machine.
Ceci va se faire grâce à un binaire qui possède le bit SUID.
On va avoir besoin de gcc pour pouvoir compiler notre code C et nous retrouver avec le fameux binaire.
apt install gcc
Notre petit programme en C va exécuter une commande comme si elle l’était directement dans le shell.
Cette commande est date. En théorie elle n’a rien de vulnérable. Et c’est le cas. Voici ce qu’on obtient en lançant simplement cette commande avec bash :
date
jeu. 14 janv. 2021 13:08:58 CET
Comme vous vous en doutez cette commande nous renvoie juste la date du jour.
La vulnérabilité du binaire ne se situe pas directement dans cette commande. On aurait pu même en appeler une autre comme id par exemple.
En fait, on va appeler la commande sans spécifier le chemin complet vers le binaire correspondant :
/bin/date
Puisqu’on l’appelle sans spécifier son chemin, on ne peut plus savoir si le binaire nommé date est vraiment celui qui est légitime ou bien s’il s’agit d’un autre qui a le même nom.
On parlera après comment exploiter cette faille.
Pour le moment voici le code C correspondant (on l’appellera check_date.c) :
#include <stdio.h>
#include <unistd.h>
int main(){
setreuid(1000, 1000);
system("echo \"Today's date is : \" ; date");
return 0;
}
Pour faire très rapide :
- setreuid permet de définir les droits d’exécution du programme. Ici en tant que l’utilisateur en utilisant ses ID (qu’on peut retrouver dans
/etc/passwd). Je vous laisse faire vos recherches sursetreuidpour savoir précisément ce que cette fonction fait. - system va lancer la commande comme si elle l’était directement dans le shell.
On va devoir ensuite le compiler avec gcc :
gcc check_date.c -o check_date
On se retrouve avec un binaire nommé check_date qu’on peut directement exécuter :
./check_date
Today's date is :
Thu Jan 14 07:17:20 EST 2021
Il ne faut pas oublier de lui rajouter le buit SUID :
chmod 4755 ./check_date
Ici c’est le 4 qui correspond au bit SUID. Ensuite on reprend la notation basique 755 pour avoir les droits rwxr-xr-x.
Je ne l’ai pas précisé avant mais il faut évidemment que le fichier appartienne à l’utilisateur sur lequel on veut se connecter :
chown krowz:krowz ./check_date
Comment exploiter cette faille ?
Comme je le disais avant, la vulnérabilité vient du fait qu’on va appeler la commande sans spécifier le chemin complet.
Quand on lance une commande, le shell va d’abord regarder la variable d’environnement nommée PATH.
On peut l’afficher simplement :
echo $PATH
/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
Il va ensuite chercher de gauche à droite dans chaque répertoire s’il trouve le binaire correspondant à la commande.
C’est à dire qu’il va chercher :
/usr/local/bin/date
/usr/bin/date
/bin/date
/usr/local/games/date
/usr/games/date
Dès qu’il va tomber sur le binaire il ne va pas chercher plus loin et l’exécute.
Dans notre cas il va trouver le binaire dans /usr/bin/date.
De plus, on peut modifier directement la variable PATH et donc ajouter de nouveaux répertoires dans lesquels on va chercher le binaire.
Maintenant si on crée un binaire qu’on appelle date dans /tmp mais qui exécute une autre commande ?
Si ensuite on ajoute /tmp dans la variable PATH ?
Et bien ce sera notre binaire date qui sera exécuté. Même si celui-ci n’affiche pas une date.
Voici les commandes correspondantes :
echo /bin/id > /tmp/date
chmod 777 /tmp/date
On va créer un nouveau fichier date qui contient la commande /bin/id et on lui donne tous les droits.
On exporte ensuite notre nouveau chemin dans la variable d’environnement PATH :
export PATH=/tmp:$PATH
Si on affiche sa nouvelle valeur :
echo $PATH
/tmp:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
On voit bien que notre /tmp a été ajouté au tout début. Et donc on va d’abord aller check dans ce répertoire.
Si on exécute de nouveau notre binaire :
Là vous vous demandez peut-être comment l’utilisateur va pouvoir deviner que le binaire va lancer la commande date sans spécifier le chemin ?
Avec la commande strings on va pouvoir afficher les chaînes de caractères lisibles qui apparaissent dans le binaire :
strings ./check_date
u/UH
[]A\A]A^A_
echo "Today's date is : " ; date
;*3$"
GCC: (Debian 8.3.0-6) 8.3.0
crtstuff.c
deregister_tm_clones
Entre toutes ces chaînes illisibles on voit bien apparaitre ce qui nous intéresse.
Maintenant essayons d’exécuter de nouveau notre binaire :
./check_date
Today's date is :
uid=1000(krowz) gid=33(www-data) groups=33(www-data)
On voit bien que le binaire est exécuté en tant que l’utilisateur de la machine.
Notre vulnérabilité et son exploitation fonctionnent !
Pour obtenir un shell rien de plus simple, dans /tmp il suffit de refaire la même manipulation mais de mettre /bin/bash dans /tmp/date plutôt que /bin/id.
echo /bin/bash > /tmp/date
chmod 777 /tmp/date
Une fois que tout fonctionne on peut supprimer notre fichier .c pour effacer les traces et ne pas que l’utilisateur ait accès au code source :
rm check_date.c
Privesc root
L’escalation de privilèges pour passer root est plus simple à configurer et à exploiter que celui précédent.
On souhaite que l’utilisateur passe root grâce à la commande man.
Pour se faire on va devoir autoriser l’utilisateur de la machine à exécuter la commande man en tant que root sans avoir besoin de mot de passe :
nano /etc/sudoers
On va ajouter la ligne suivante :
krowz ALL=(root) NOPASSWD: /usr/bin/man man
Désormais l’utilisateur peut lancer la commande /usr/bin/man man avec sudo et le mot de passe ne sera pas demandé.
Comment exploiter cette faille ?
Il faut que l’utilisateur réussisse à obtenir un shell root. Et il ne peut utiliser que la commande /usr/bin/man man.
Lorsqu’on fait un man d’une commande on ouvre dans le shell une page de manuel qui contient des informations sur le binaire spécifié par la commande.
Ainsi man bash va nous donner le manuel d’utilisation pour bash.
Lorsqu’on est dans ce manuel on peut exécuter des commandes.
Voici la marche à suivre :
sudo /usr/bin/man man
Une fois dans le manuel :
!/bin/bash
On entre et nous voilà root !
Dernières modifications
Il nous reste maintenant à modifier tous les mots de passe de la machine pour que l’utilisateur qui tente de hacker la machine ne puisse pas brute force et donc passer à côté du chemin défini.
Pensez également à modifier les droits des fichiers. Par exemple, tout ce qui se situe dans /var/www/html doit appartenir à www-data :
chown -R www-data:www-data /var/www/
Important aussi ! Pensez à supprimer le fichier .bash_history situé dans tous les répertoires des utilisateurs. Ce fichier contient toutes les commandes tapées et donc ça peut donner de gros indices à l’utilisateur qui souhaite faire la box.
Il est généré automatiquement donc je vous conseille de faire un lien symbolique qui redirige vers /dev/null. Comme ça il sera toujours vide :
rm .bash_history
ln -s /dev/null .bash_history
ls -la
lrwxrwxrwx 1 krowz krowz 9 Jan 14 09:09 .bash_history -> /dev/null
N’oubliez pas de le faire pour le compte root également.
Pour finir on peut ajouter les flags dans les fichiers et mettre les bons propriétaires :
echo "01846f86f9285ca468eb3618db462ab1" > /home/krowz/user.txt
chown krowz:krowz /home/krowz/user.txt
chmod 600 /home/krowz/user.txt
echo "b1970313271d6e36bb343cd8e671b087" > /root/root.txt
chown root:root /root/root.txt
On met le droit de lecture uniquement sur l’utilisateur pour que quand on arrive en tant que www-data on ne puisse pas directement lire le flag. Il faut d’abord faire la première élévation de privilèges pour y avoir accès.
Essais globaux
La configuration de chaque service et des escalations de privilèges est terminée. Normalement à cette étape chaque configuration fonctionne correctement.
On va ici tenter de hack la machine de la manière dont elle a été pensée (ou pas pour trouver de potentielles vulnérabilités qui n’ont pas été pensées).
Je ne vais pas le refaire ici parce que l’article est déjà suffisamment long mais je vous incite à le faire de votre côté !
Mise en ligne et diffusion
Vous avez désormais une machine vulnérable fonctionnelle et prête à se faire hacker. Il ne vous reste plus qu’à la partager au monde entier.
On va partir du principe que vous voulez la partager à vos amis.
Grâce à VirtualBox on va pouvoir exporter notre image sous le format .ova.
Pour se faire c’est très simple, on doit tout d’abord éteindre la VM de la machine vulnérable.
On va ensuite faire un clic droit sur la machine dans la liste à gauche puis sélectionner Export to OCI :
Vous pouvez modifier le chemin vers lequel l’image sera exportée puis Suivant et enfin Export.
Bravo à vous, vous pouvez désormais upload cette image sur une plateforme de partage comme Mega par exemple.
Conclusion
Un grand merci à tous ceux qui ont eu le courage de finir cet article.
J’espère qu’il vous aura plu et que ça vous a donné des tonnes d’idées pour créer vos propres machines vulnérables.
N’hésitez pas à me faire vos retours directement en me contactant sur Twitter ou bien en rejoignant mon serveur Discord.
Bonne création et bon hacking !